
In the rapidly evolving field of artificial intelligence, a groundbreaking approach to reinforcement learning (RL) has emerged, promising to significantly improve the efficiency and effectiveness of robot learning. The paper “Reinforcement Learning with Action-Free Pre-Training from Videos” introduces APV (Action-Free Pre-training from Videos), a novel framework that leverages the power of video data to enhance the learning capabilities of RL agents. Let’s dive deep into this innovative approach and explore its implications for the future of AI and robotics.
The Challenge of Sample Efficiency in RL
Reinforcement learning has shown remarkable success in solving complex decision-making problems, from game-playing to robotic control. However, traditional RL methods often require vast amounts of interaction with the environment to learn effective behaviors. This “sample inefficiency” poses a significant barrier to the practical application of RL in real-world scenarios, especially in robotics where data collection can be time-consuming and expensive.
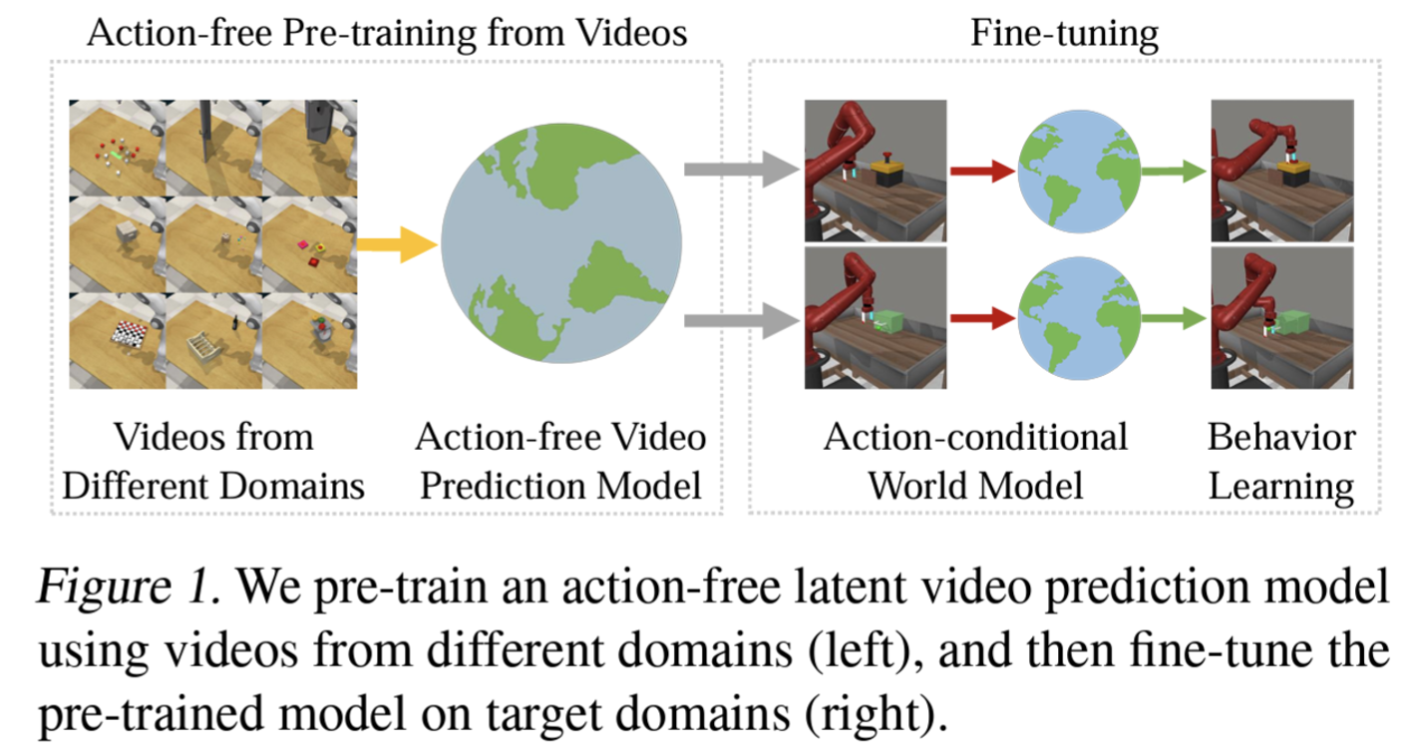
Enter APV: A Two-Phase Approach
The APV framework addresses this challenge by introducing a two-phase approach:
- Action-Free Pre-Training: In this phase, the system learns to predict future states from video data alone, without any action information. This allows the model to leverage large datasets of readily available videos, even from domains different from the target task.
- Fine-Tuning for Specific Tasks: The pre-trained model is then fine-tuned on a smaller set of action-labeled data for the specific task at hand.
Key Components of APV
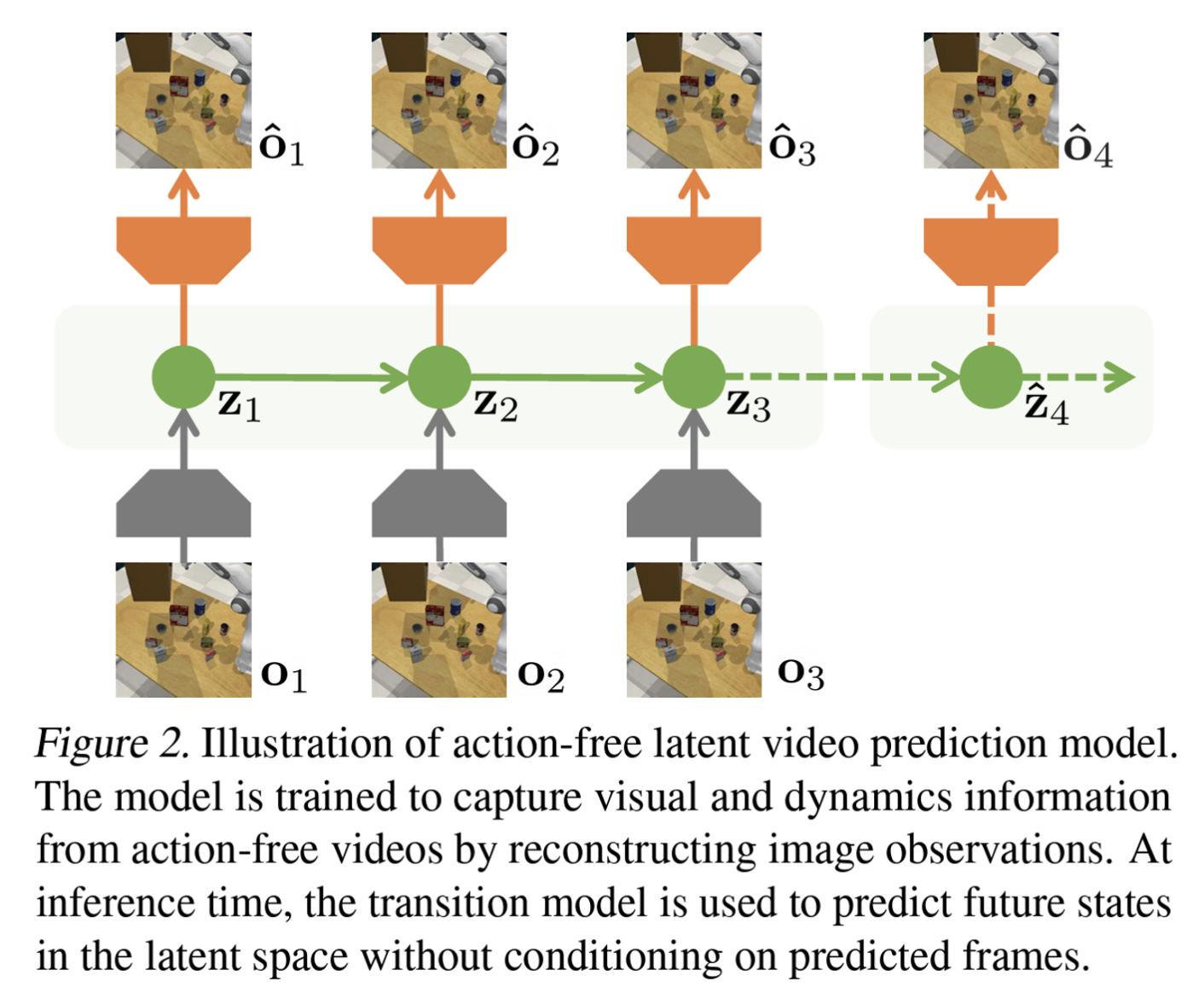
- Action-Free Latent Video Prediction Model:
- This model learns to predict future states in a latent space, capturing the dynamics of the environment without relying on action information.
- It consists of a representation model, a transition model, and an image decoder.
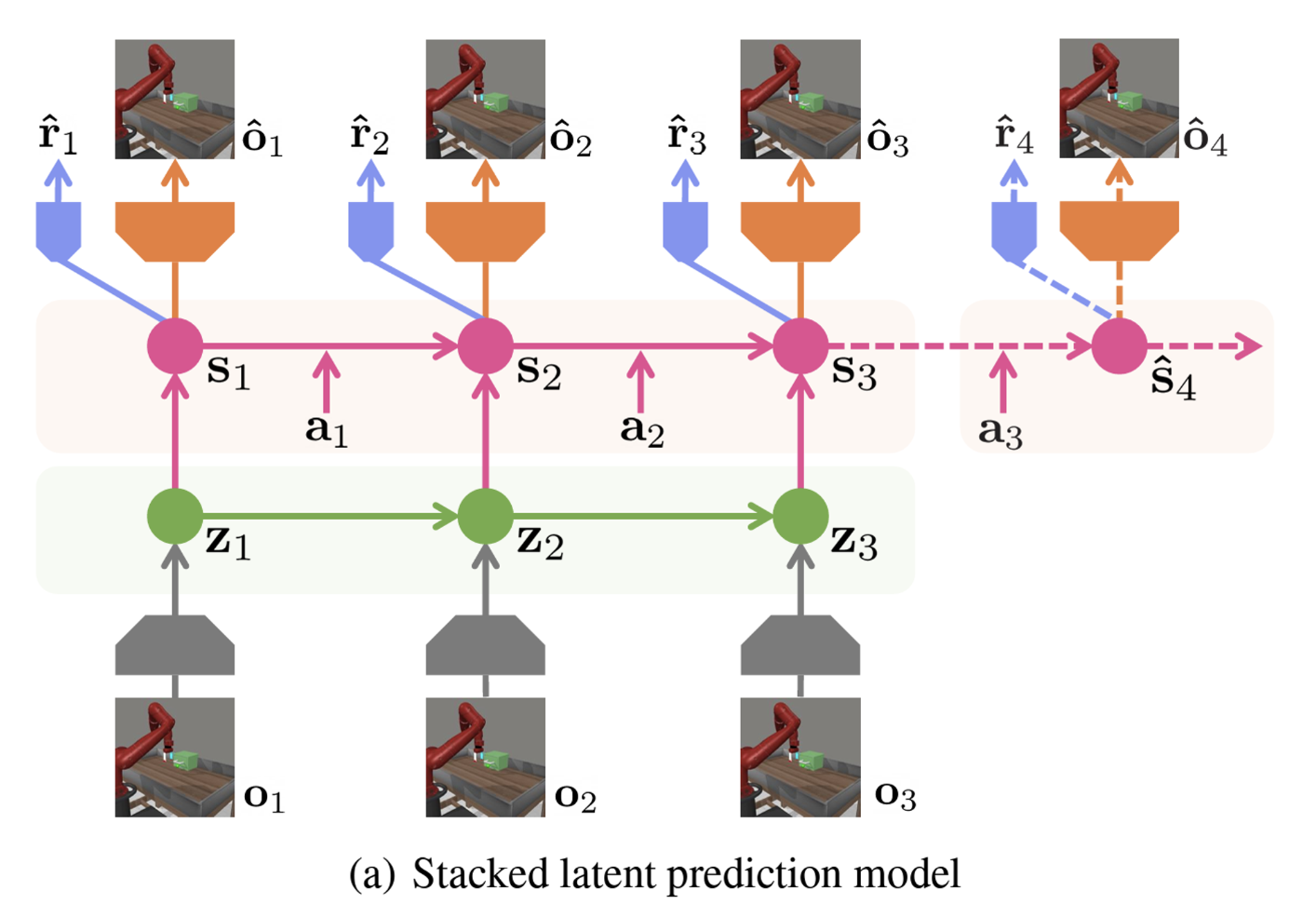
- Stacked Latent Prediction Model:
- During fine-tuning, an action-conditional prediction model is stacked on top of the pre-trained action-free model.
- This architecture allows the system to incorporate action information while preserving the knowledge gained from pre-training.
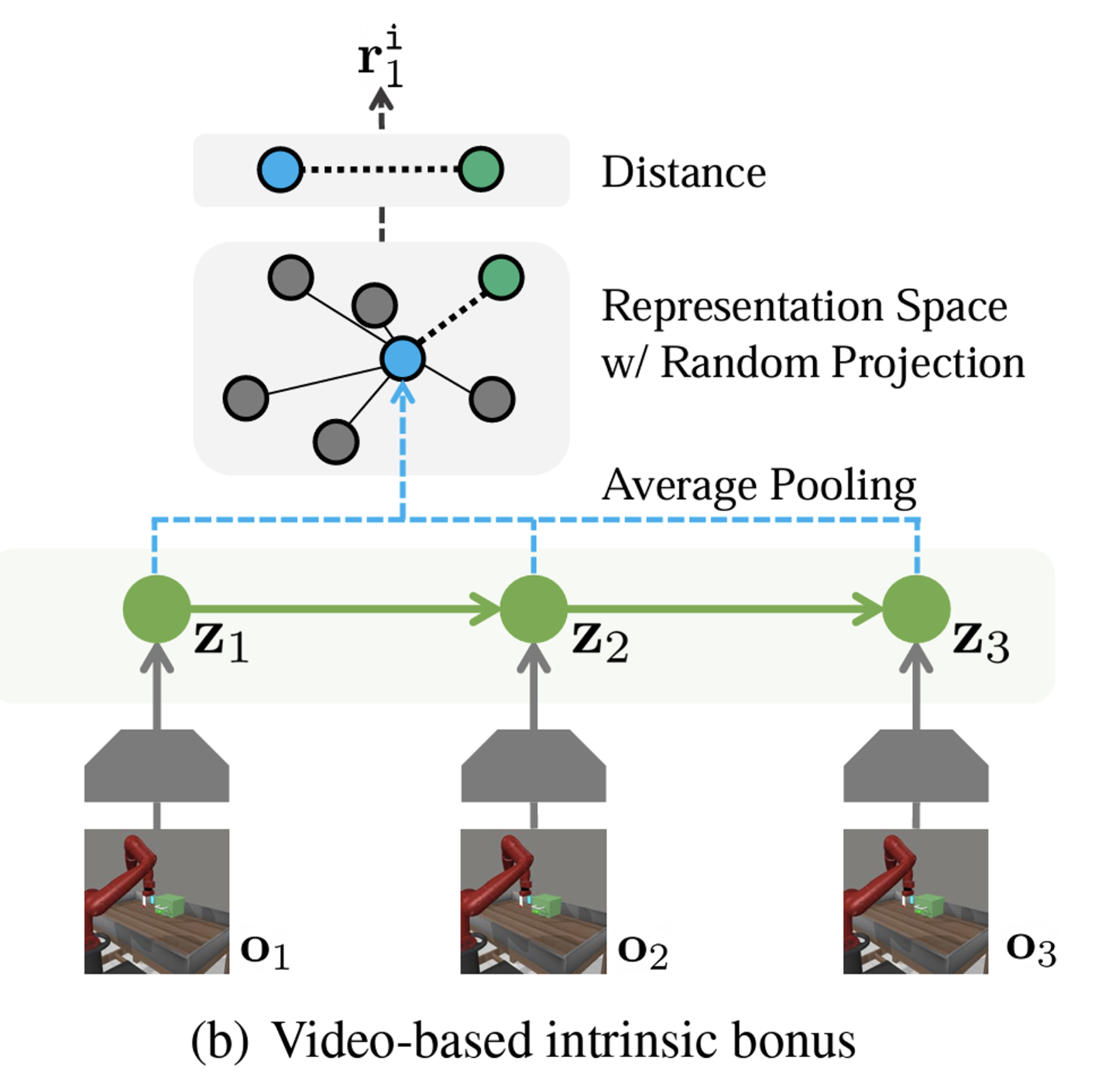
- Video-Based Intrinsic Bonus:
- To encourage exploration, APV introduces an intrinsic reward based on the diversity of visited trajectories.
- This bonus leverages the pre-trained representations, promoting more effective exploration.
Impressive Results
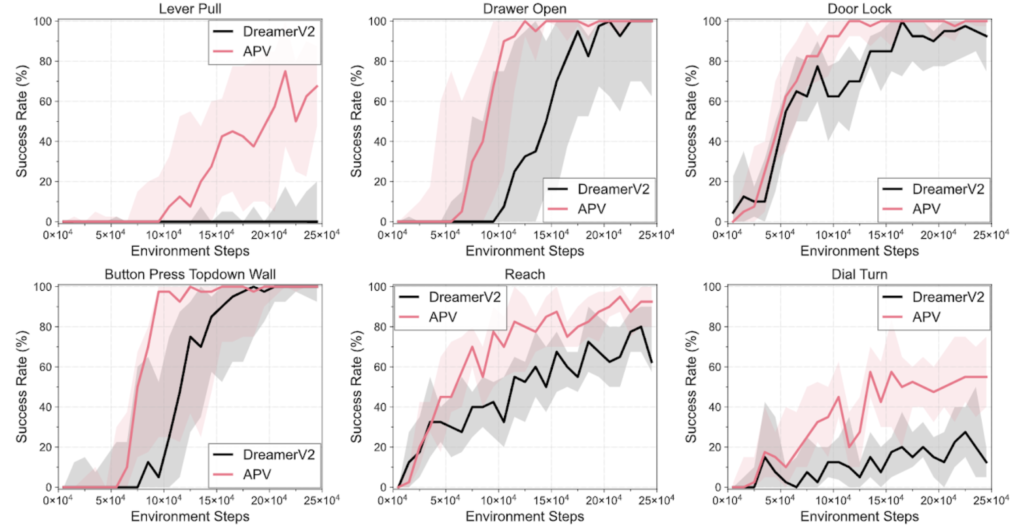
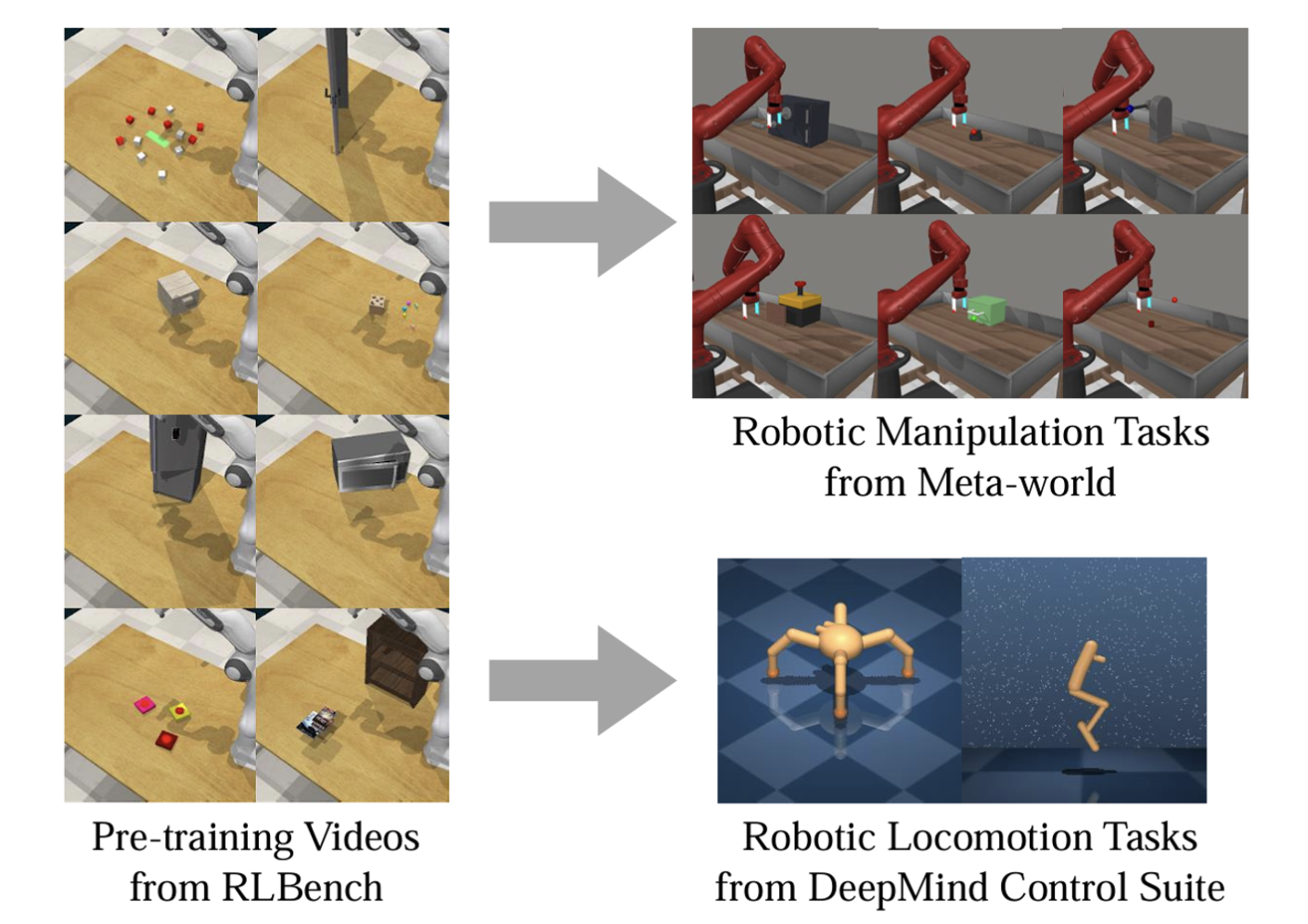
The researchers evaluated APV on a wide range of tasks, including robotic manipulation in Meta-world and locomotion tasks in DeepMind Control Suite. The results are striking:
- APV consistently outperformed state-of-the-art baselines, including DreamerV2, in terms of sample efficiency and final performance.
- On Meta-world manipulation tasks, APV achieved a 95.4% aggregate success rate, compared to 67.9% for DreamerV2.
- Remarkably, representations pre-trained on manipulation videos from RLBench transferred effectively to locomotion tasks in DeepMind Control Suite, despite the significant differences in visuals and objectives.
Key Insights and Implications
- Leveraging Diverse Video Data: APV demonstrates the potential of learning from readily available video data, even when it comes from different domains. This opens up vast possibilities for pre-training RL agents using the wealth of video content available online.
- Efficient Transfer Learning: The success in transferring knowledge from manipulation videos to locomotion tasks highlights the framework’s ability to capture generalizable dynamics information.
- Structured Representations: By focusing on predicting trajectories of points rather than full pixel-level video prediction, APV provides a more efficient and physically grounded representation for RL.
- Exploration through Diversity: The video-based intrinsic bonus encourages agents to explore in a more structured, long-term manner, leading to the discovery of more diverse behaviors.
Limitations and Future Directions
While APV shows great promise, the authors note some limitations and areas for future research:
- Real-World Videos: The current implementation struggles with complex, real-world video datasets. Developing more robust video prediction models for diverse, unconstrained videos is an important next step.
- Action-Labeled Data: APV still requires some action-labeled demonstration data for fine-tuning. Exploring ways to eliminate this requirement, perhaps through reinforcement learning techniques, could further improve the framework’s applicability.
- Scaling Up: Investigating how APV performs with larger model architectures and more diverse pre-training datasets could lead to even more impressive results.
Conclusion
APV represents a significant leap forward in the quest for more sample-efficient and generalizable reinforcement learning. By bridging the gap between large-scale video datasets and robotic skill learning, this framework opens up exciting possibilities for scaling up robot learning using widely available video data.
As research in this area continues, we can look forward to robots that can learn increasingly complex skills from the vast array of instructional videos and demonstrations available online. The implications for fields like robotics, autonomous systems, and artificial general intelligence are profound, potentially accelerating the development of more capable and adaptable AI systems.
The APV framework not only advances the state-of-the-art in imitation learning from videos but also demonstrates the power of carefully designed structured representations in AI and robotics. As we move forward, it’s clear that leveraging diverse data sources and developing more efficient learning algorithms will be key to unlocking the full potential of artificial intelligence in real-world applications.

