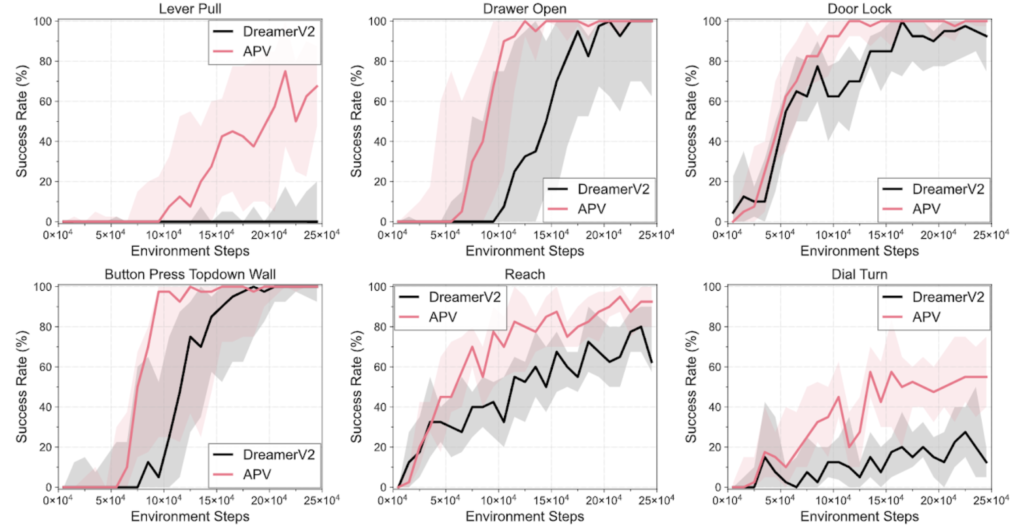
Hello and welcome to the first blog post in my new series, Machine Learning Mastery. In this article, I’m going to be giving you an introduction to machine learning.
So I want you to imagine a world where diseases are predicted before symptoms appear, where your car knows your destination before you say a word, and where your financial security is constantly monitored against fraud risks.
Welcome to the extraordinary world of machine learning—a field of artificial intelligence that’s not just transforming the future, but reshaping our present.
Today, machine learning algorithms are at the heart of many technological advancements, profoundly influencing industries and everyday life. But what exactly is machine learning? How does it function, and why is it so pivotal in the trajectory of modern technology and innovation?
In this series, we will unravel the complexities of machine learning, explore its various types, and understand its role as a cornerstone in the broader landscape of artificial intelligence and data science. Whether you’re a student, a professional, or simply curious about the technologies shaping our world, you’re in the right place to start demystifying these advanced concepts.
Let’s start with a couple definitions.
Artificial Intelligence
Technology that enables computers and machines to simulate human intelligence and problem-solving capabilities
Machine Learning
A subfield of artificial intelligence that gives computers the ability to learn from data through statistical algorithms and generalize to unseen data without explicitly being programmed
Applications of Machine Learning

Image recognition, translation, fraud detection, chatbots, generative ai, speech recognition, self driving cars, recommendation systems, and assessing medical conditions. Machine learning can be applied to pretty much every industry, from healthcare to e-commerce
Key Terms
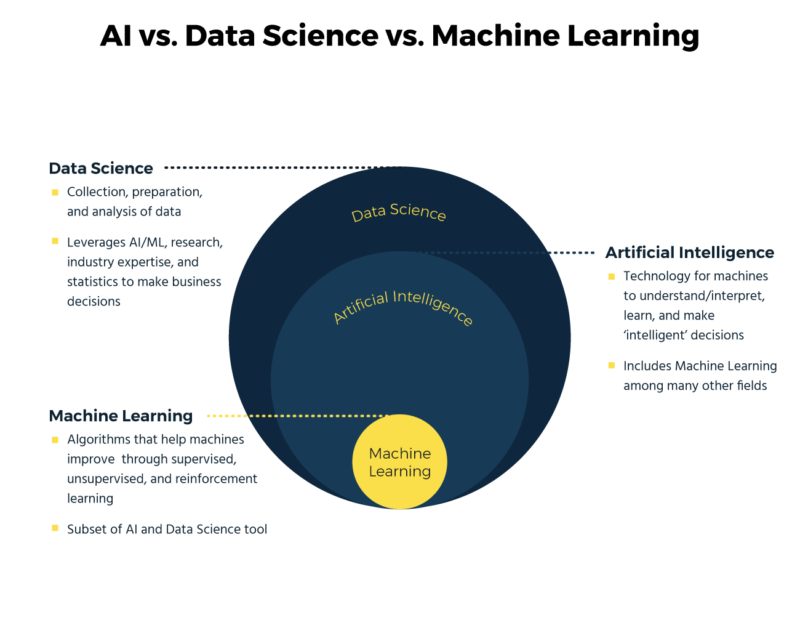
Artificial Intelligence (AI) is the broad discipline in computer science focused on creating systems capable of performing tasks that typically require human intelligence. This includes everything from reasoning and learning to interacting with the environment.
Machine Learning (ML), a subset of AI, specifically deals with algorithms and statistical models that enable computers to perform specific tasks based on recognizing patterns and making inferences from data, without being explicitly programmed for each task.
Data Science is an interdisciplinary field that utilizes scientific methods and systems to extract insights and knowledge from data, both structured and unstructured. It overlaps with machine learning when employing algorithms to analyze data and make predictions.
Interrelation and Differences:
- AI represents the overarching goal of automating intelligent behavior. Under this umbrella, ML provides the techniques and tools to achieve such automation by learning from data.
- Data Science uses broader analytical techniques, including machine learning, to derive insights and inform decision-making. It is not only concerned with automating tasks but also with understanding data patterns, predicting trends, and making data-driven decisions.
Some Examples:
- AI: Developing a voice-activated assistant that can understand spoken language and perform tasks based on commands.
- ML: Implementing a recommendation system that suggests products based on a user’s past shopping behavior.
- Data Science: Analyzing large sets of customer data to identify key demographics for targeted marketing campaigns.
Types of Machine Learning
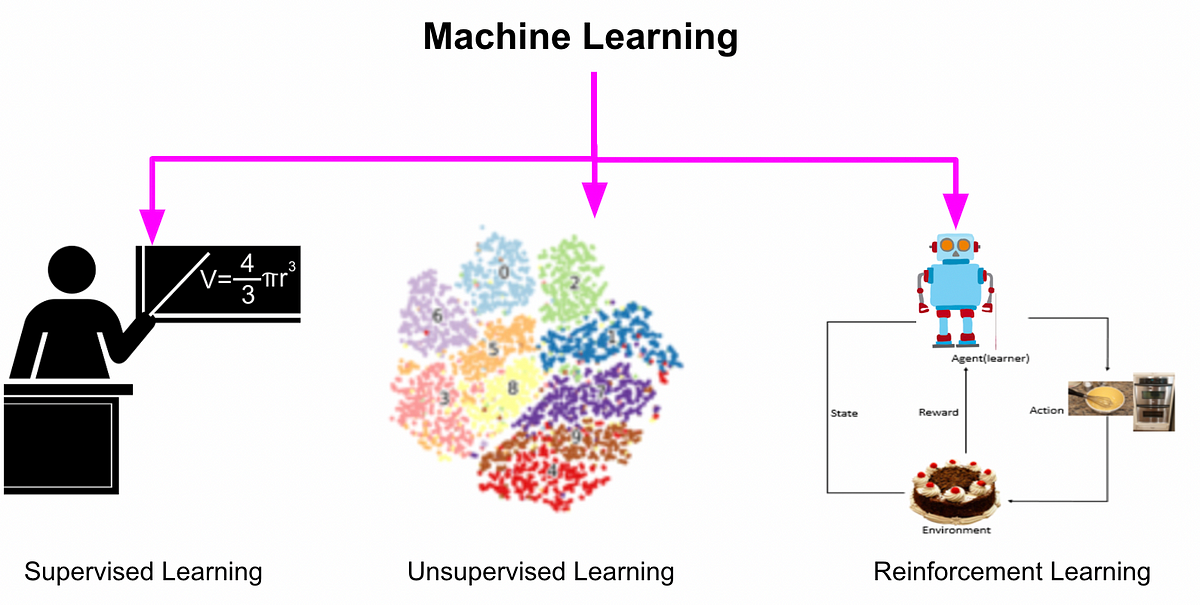
These are the main types of machine learning, supervised, unsupervised, and reinforcement learning. Let’s talk about each of them. Keep in mind we’ll go in depth into these main types of machine learning in future blog posts.
Supervised Learning
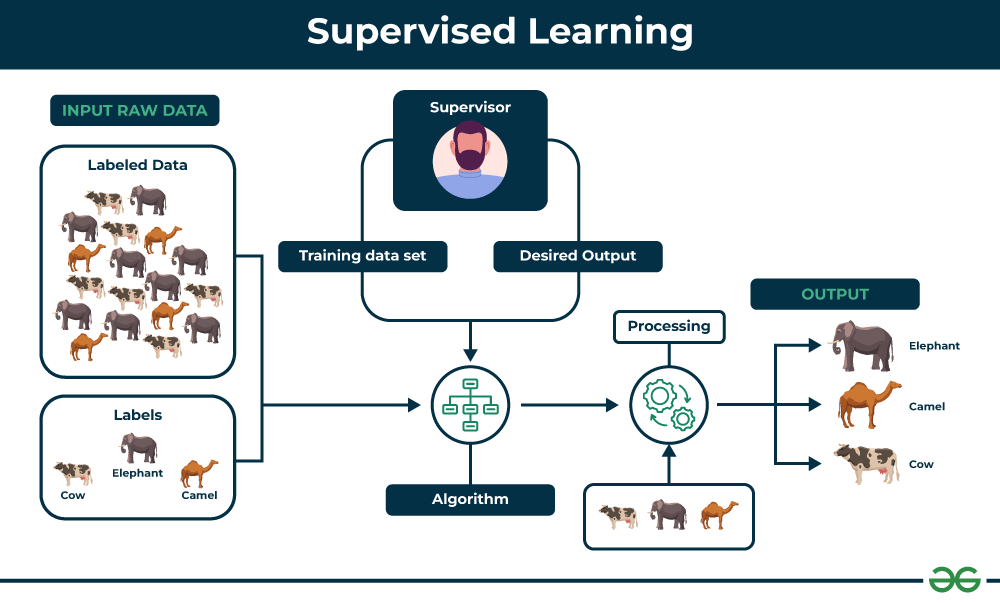
So first off, supervised learning is a type of machine learning where the model learns from labeled data. This means that each piece of data in the training set, or the data that the model learns from, is already tagged with the correct answer or output.
Now, what even is a model? A model is a program that can find patterns or make decisions from a previously unseen dataset. The goal here is for the model to learn a mapping from inputs to outputs.
Common applications include image classification, where the model predicts what’s in a photo, and spam detection in emails. Techniques used in supervised learning range from simple regressions to complex neural networks.
We’ll talk more about regression in a future post and talk about neural networks in an upcoming series on deep learning.
Unsupervised Learning
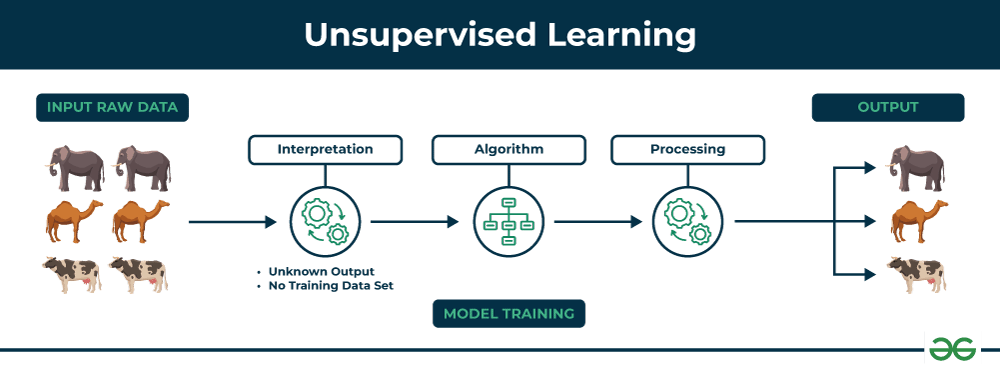
Unsupervised Learning involves learning from data that hasn’t been labeled. The model’s task is to uncover underlying patterns or structures from the data itself. For instance, in customer segmentation, unsupervised learning algorithms can group customers with similar behaviors without prior labeling.
Other applications include anomaly detection where the system identifies unusual data points that do not fit any set of patterns. Key techniques include clustering and dimensionality reduction methods like Principal Component Analysis, which we’ll talk more about in the post on unsupervised learning.
Bonus: Self-supervised Learning
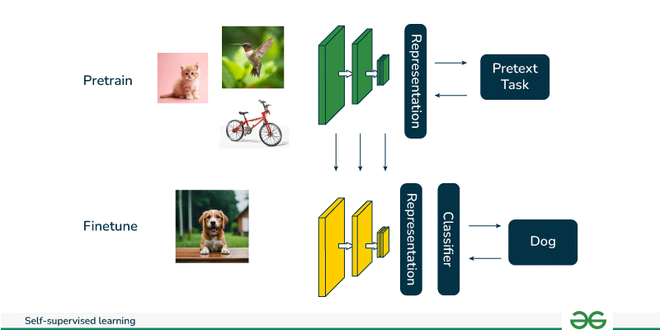
Self-supervised learning is where the model generates its own labels from the data by completing pretext tasks, such as predicting missing parts of an image or text. This process helps the model understand the underlying structure of the data without needing external labels.
It’s often used instead of traditional unsupervised learning because it teaches the model specific tasks that enhance its ability to generalize on unseen data. This method of self-supervised learning is especially valuable when large amounts of unlabeled data are available but labeled data is scarce.
Bonus: Semi-supervised Learning
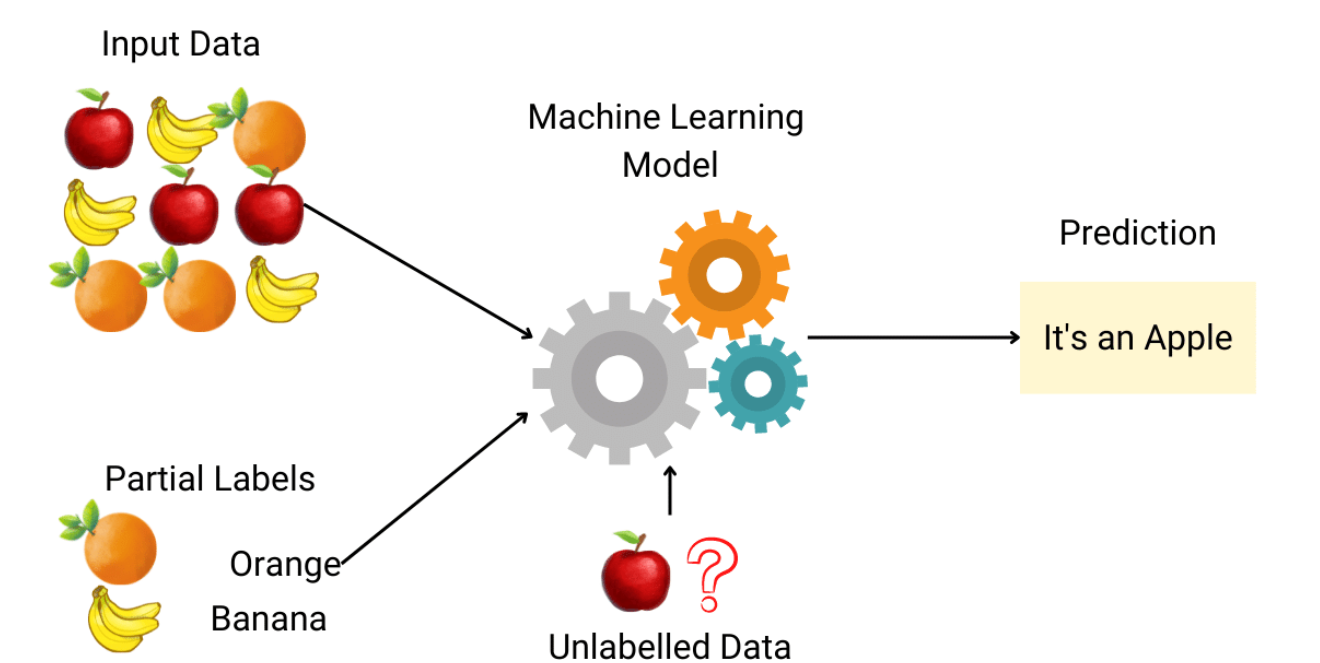
Semi-supervised learning mixes both labeled and unlabeled data, which is particularly useful when labels are expensive or difficult to obtain. This method leverages the small amount of labeled data to improve the learning accuracy using a large pool of unlabeled data.
For instance, in image recognition, semi-supervised techniques can help improve the model’s performance without needing a label for every single image.
Techniques such as label propagation and using generative models are common in this field. Basically, you would train your model on the labeled data, and use that model to predict labels for the unlabelled data, then add the newly labeled data to your training set. Or you could use a pre-trained generative model to generate labels on your data.
Reinforcement Learning
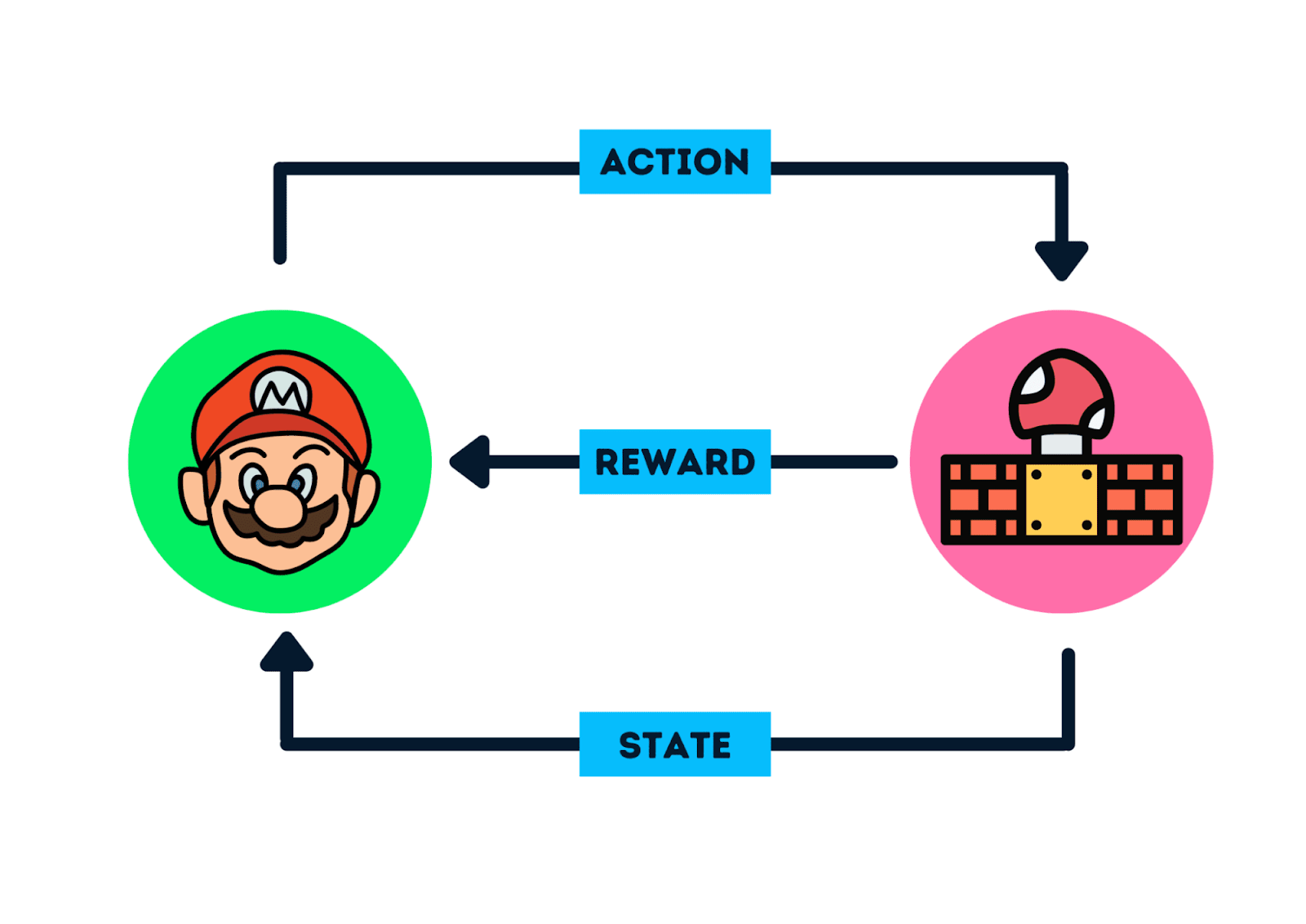
Finally, Reinforcement Learning is all about making decisions sequentially.
The model learns to achieve a goal in an environment that offers complex and uncertain challenges. It does this through trial and error, using rewards and punishments as signals.
Common applications include training AI to play video games, developing autonomous driving systems, and robotic learning. Techniques such as Q-learning and policy gradients help guide the learning process towards optimal decision-making.
Yann’s Cake
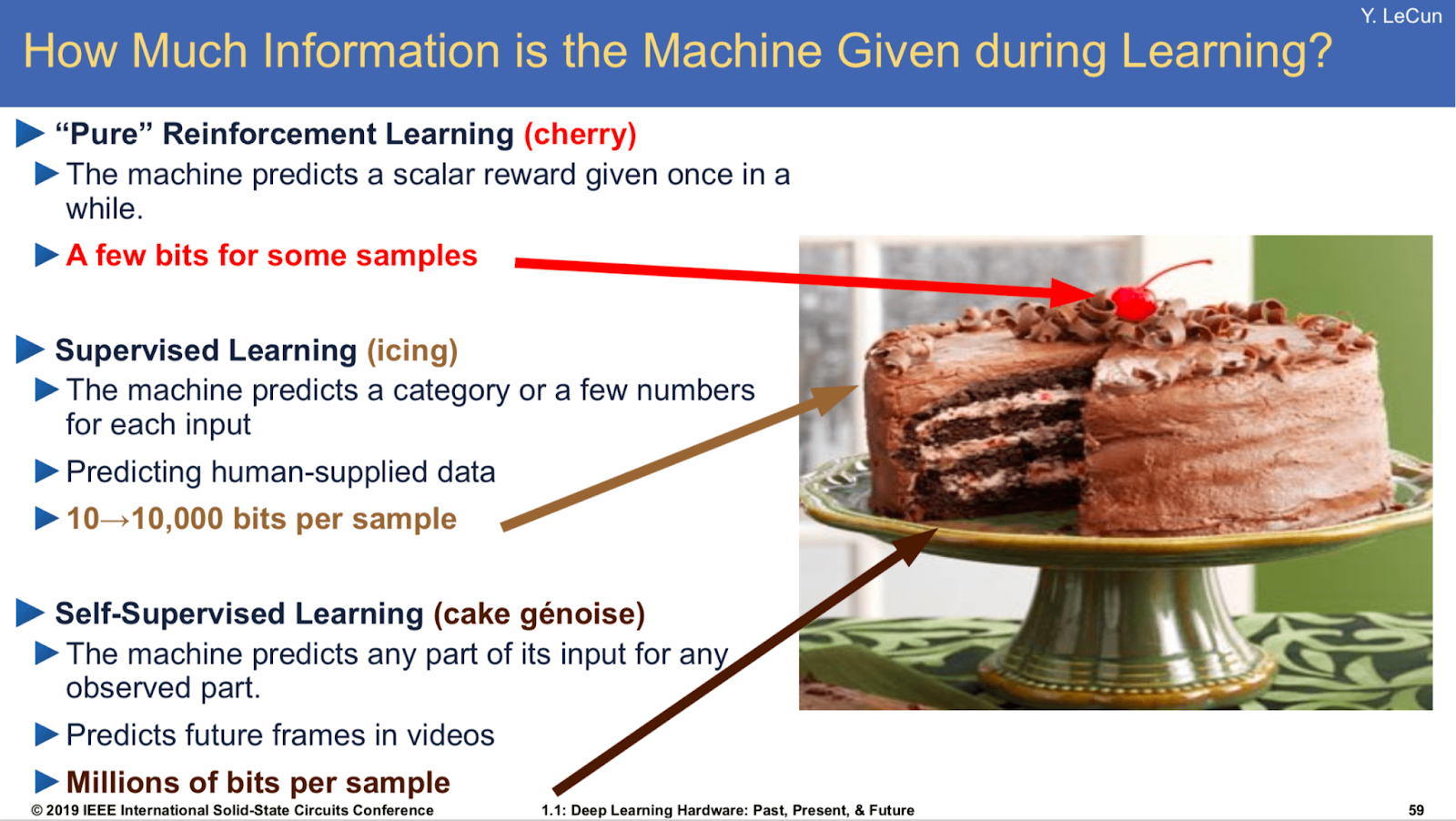
Now that you know about the different types of machine learning, I’ll let you in on a popular meme in the AI community. Yann Lecun, a very important figure in the AI and ML community, even called a godfather of AI, gave a talk in which he compares human learning, animal learning, and general intelligence to comprise of the parts of a cake.
Self-supervised learning being the actual cake, supervised learning being the icing, and pure reinforcement learning being the cherry on top.
Yann later replaces the term, self-supervised learning with unsupervised learning because as he says, self-supervised learning uses way more supervisory signals than supervised learning, and enormously more than reinforcement learning. That’s why calling it “unsupervised” is totally misleading.
This just goes to show how some of these terms are still evolving and how the definitions are still under discussion in the community.
Math in Machine Learning
Now, at their core, machine learning algorithms are just math which is why we’ll be spending the next post covering the fundamentals of math that you’ll definitely need to know to become a machine learning expert.
We’ll go over the basics of algebra, statistics and probability, linear algebra, and calculus. If you’re familiar with these topics and have above a high school level knowledge of mathematics, you can just skip the next post which is the math primer.