In the world of robotics, learning complex manipulation skills from video data has been a long-standing challenge. A groundbreaking new paper, “Any-point Trajectory Modeling for Policy Learning,” introduces an innovative approach that could revolutionize how robots learn from visual information. Let’s explore this exciting development in detail.
The Challenge of Learning from Videos
While videos are rich in information about behaviors, physics, and semantics, extracting actionable knowledge for robot control has been difficult due to the lack of action labels. Previous approaches, such as video prediction models, have struggled with computational demands and often produced unrealistic predictions.
Introducing Any-point Trajectory Modeling (ATM)
Researchers have developed a novel framework called Any-point Trajectory Modeling (ATM). The core idea is to pre-train a model that can predict the future trajectories of arbitrary points within a video frame, conditioned on a task instruction. This approach offers several key advantages:
- It provides a structured representation bridging video pre-training and policy learning.
- It naturally incorporates physical inductive biases like object permanence.
- It’s computationally efficient compared to full video prediction.
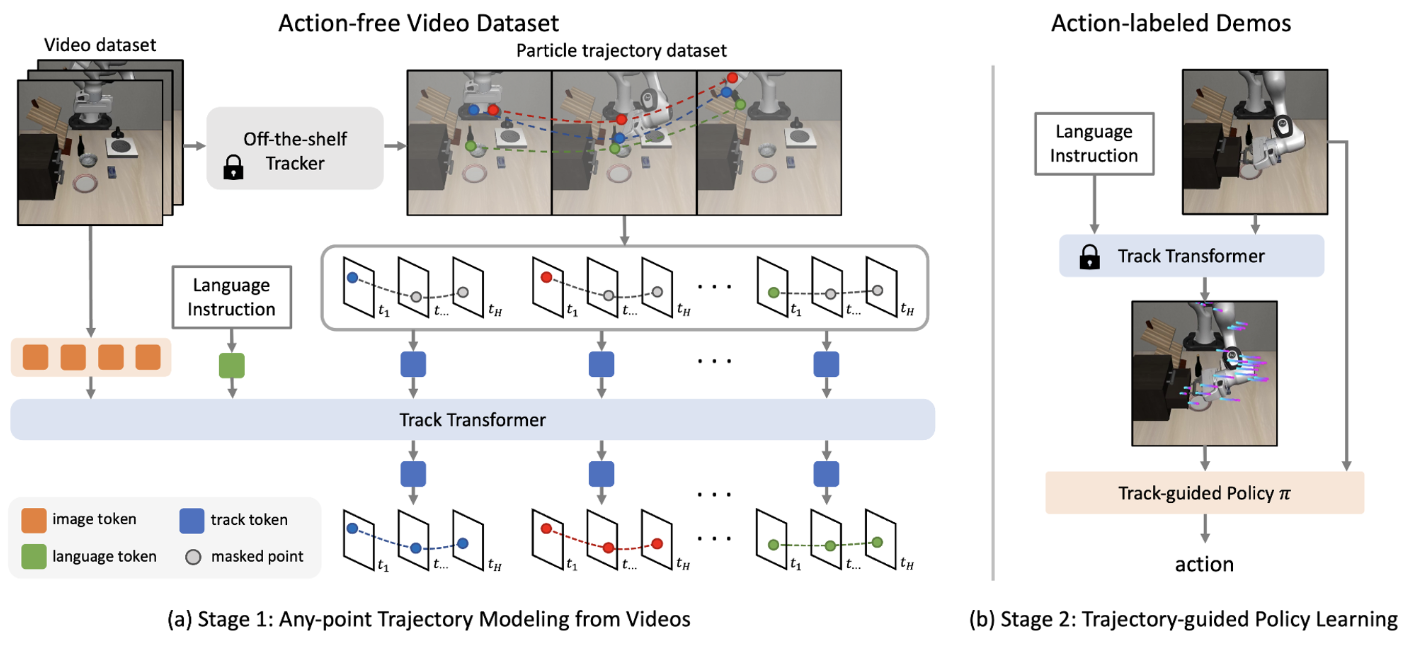
How ATM Works: A Detailed Look
- Video Pre-processing and Track Generation
The process begins with an action-free video dataset. For each video:
a) A random frame is selected.
b) An off-the-shelf tracker (CoTracker) generates trajectories for points across the video.
c) A filtering step focuses on informative points:
- Static points are filtered out.
- New points are sampled around areas with more movement.
This results in a set of trajectories capturing meaningful motion in the video.
- Track Transformer Pre-training
The heart of ATM is the Track Transformer, which learns to predict future point trajectories:
a) Input: Current image observation, initial point positions, and language instruction.
b) Output: Predicted future positions of the input points.
c) Architecture: Uses a transformer-based model, encoding different modalities into a shared embedding space.
d) Training Process: Future point positions are masked, and the model learns to reconstruct these positions. An auxiliary task of reconstructing masked image patches is also used.
- Policy Learning with ATM
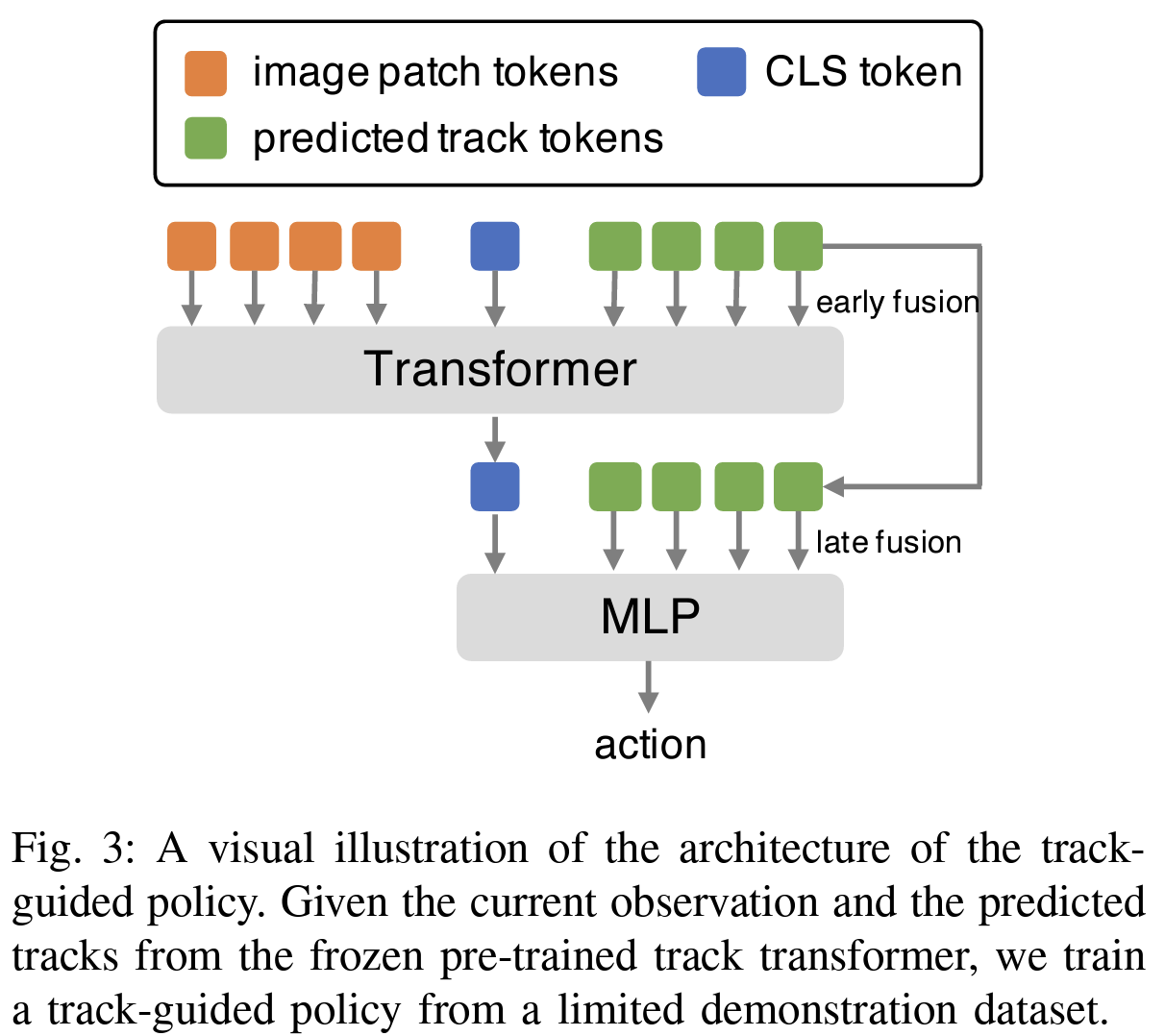
Once pre-trained, the Track Transformer guides policy learning:
a) Track Generation: During policy training/execution, a fixed grid of 32 points is used for efficiency.
b) Policy Architecture: Uses a Vision Transformer (ViT) based architecture, taking as input stacked image observations, proprioception data, and predicted trajectories.
c) Policy Components:
- Spatial Encoding processes each timestep’s data.
- Temporal Decoding integrates information across time.
- Action Head predicts actions based on the processed information.
d) Track Integration: Uses both early fusion (input with image patches) and late fusion (before action prediction).
e) Training: Uses a small set of action-labeled demonstrations with behavioral cloning.
- Execution
During task execution:
a) The policy receives the current observation and task instruction.
b) It queries the Track Transformer to predict future trajectories.
c) These predicted trajectories serve as detailed subgoals.
d) The policy uses this guidance to determine the next action.
e) This process repeats at each timestep, allowing for closed-loop control.
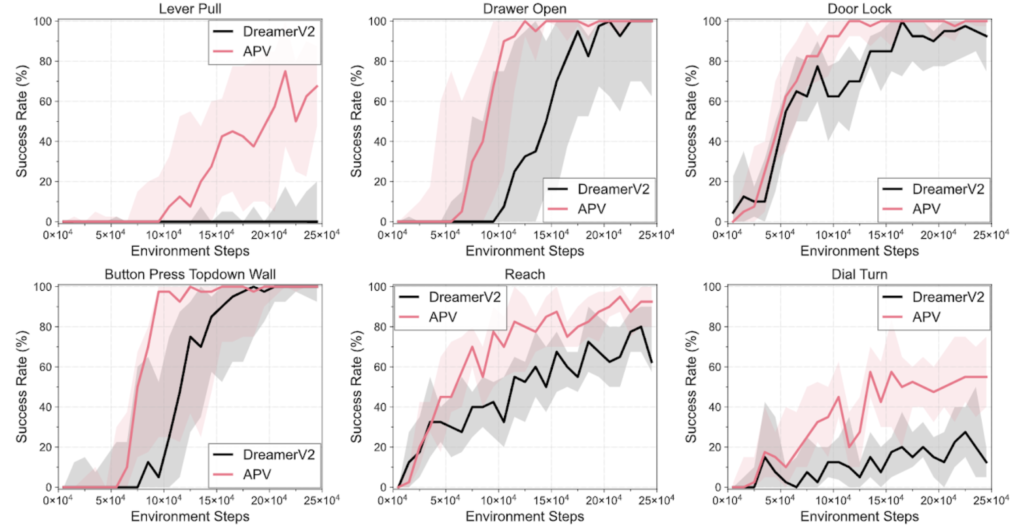
Impressive Results
The researchers evaluated ATM on over 130 language-conditioned manipulation tasks in both simulation and the real world:
- ATM outperformed strong video pre-training baselines by 80% on average.
- It achieved a 63% success rate compared to 37% for the best previous method.
- ATM demonstrated effective transfer learning from human videos and videos from different robot morphologies.
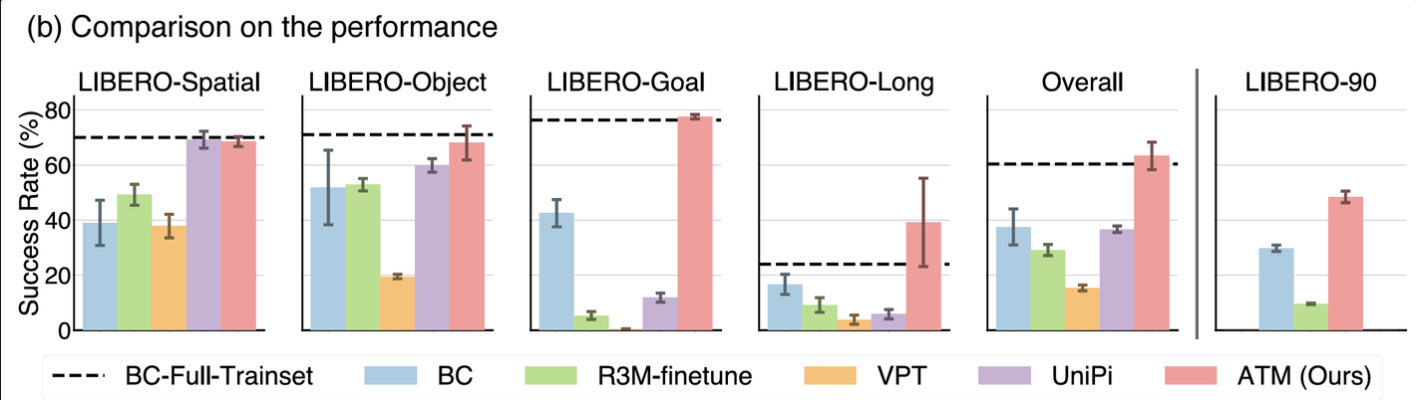
Comparisons to Baselines
ATM was tested against several state-of-the-art approaches:
- Behavioral Cloning (BC)
- R3M (a contrastive learning method)
- Video PreTraining (VPT)
- UniPi (a video prediction approach)
ATM consistently outperformed these baselines across different task suites, showcasing its effectiveness in leveraging video data for policy learning.

Real-World Validation
The researchers also tested ATM on a real UR5 robot arm, where it again showed significant improvements over baselines on language-conditioned manipulation tasks.

Learning from Human Videos
One of the most exciting aspects of ATM is its ability to learn from out-of-distribution videos, including human demonstrations. This opens up vast possibilities for leveraging widely available human instructional videos for robot learning.
Why It Works: Key Insights
- Structured Representation: By focusing on point trajectories rather than pixel-level details, ATM captures the essential dynamics of a task.
- Efficient Computation: Predicting trajectories is much less computationally intensive than full video prediction, allowing for closed-loop execution during policy rollouts.
- Dense Guidance: The predicted trajectories provide detailed step-by-step guidance for the policy, acting as a motion prior.
Limitations and Future Work
While ATM shows great promise, the authors note some limitations:
- It still requires some action-labeled demonstration data for final policy learning.
- The current work focuses on videos with small domain gaps. Adapting to in-the-wild videos poses additional challenges.
Future research directions could include:
- Using reinforcement learning to eliminate the need for action-labeled demonstrations.
- Extending ATM to work with more diverse and unconstrained video datasets.
Conclusion
Any-point Trajectory Modeling represents a significant leap forward in bridging the gap between large-scale video datasets and robotic skill learning. By providing a structured, efficient, and generalizable approach to extracting control-relevant information from videos, ATM opens up exciting possibilities for scaling up robot learning using widely available video data.
This work not only advances the state-of-the-art in imitation learning from videos but also demonstrates the power of carefully designed structured representations in AI and robotics. As research in this area continues, we can look forward to robots that can learn increasingly complex skills from the vast array of instructional videos available online.
The decomposition of the challenging visuomotor policy learning problem into learning “what to do” from videos (via trajectory prediction) and learning “how to do it” from a small set of robot demonstrations is a key innovation. This approach allows ATM to excel across a wide range of manipulation tasks and opens new avenues for more efficient and generalizable robot learning methods.